Garbage collection basics
June 1, 2019
This is the start of a semi-regular series of articles I’m hoping to write, time-permitting, looking at interesting things I’ve run into, discovered, or failed miserably to comprehend whilst working on Catnip. A lot of this is going to be a bit ad-hoc, so apologies in advance for any errors or omissions - criticism or corrections are both greatly appreciated at contact@shironekolabs.com!
One of the more interesting concepts in writing a C# runtime, or for that matter managed languages in general, is that of garbage collection. So I thought I’d write a little bit about how it works, and specifically why doing GC in a manner that doesn’t involve bringing the whole program to a screeching halt is a lot harder than it might first appear. But before we can get to that topic, we need to establish some fundamentals.
So what is garbage collection about? Well, quite simply, it takes the act of freeing memory out of the hands of the application developer and makes it automatic. This is (in broad terms) a good idea for two reasons:
1) Working out when memory needs to be freed in complex applications is hard, and making sure it happens correctly under all circumstances is even harder. As soon as you have objects that are shared by multiple systems, exceptions, threading or any combination of the above, the problem rapidly becomes almost unworkable. Most significantly-sized programs written in environments without automatic memory management end up having to invent their own rules or semi-automatic systems (such as shared_ptr and friends in C++) to keep this complexity at a level where mere humans can be expected to reason about it sensibly.
2) Manual memory management makes certain security and reliability constraints almost impossible to guarantee - if an application is able to free memory at will, this also implies that it can try to access that memory after it has freed it, likely resulting in heap corruption or other unpleasantness. In an environment like the CLR where a design goal of the system is that untrusted application code can be run safely alongside trusted code in a sandbox, this would be exceptionally hard to work with (or require a lot of expensive runtime checks to ensure it could never happen).
So to put it in concrete terms, the goal of automatic memory management is to “free memory when it is no longer being used by the application, but not before”. It’s also desirable that memory be freed as soon as possible, but this isn’t a hard constraint - whilst freeing an object too early will generally result in a crash or other catastrophic failure, freeing an object too late is simply less efficient in terms of overall memory usage.
Within automatic memory management, “garbage collection” is a fairly broad term, and can refer to a variety of different techniques. The two most commonly used are “object graph tracing” (which is itself often referred to as simply “garbage collection”), and reference counting (as used by Python, ARC and others). But for now let’s focus on object graph tracing as that’s what every implementation of the CLR (that I’m aware of) uses.
Interestingly, it is not a requirement to use object tracing for a CLR implementation - the EMCA standard is non-specific about the method used to manage memory, and it would be perfectly possible to write a fully-compliant implementation based on reference counting, for example.
Object graph tracing is based on a single very simple observation - if we assume that every object in the heap is allocated at an address assigned by the memory manager, and the user promises only to access objects using pointers that were given to it by the memory manager (so no “making up” addresses, performing maths operations on them, or similar), then a given object is only accessible if the program has a pointer to it stored somewhere.
And the next logical step in this chain of thought is to consider the list of places that the program can store a pointer. In fact, we can fairly simply enumerate the list of places that a program can store any kind of data:
- Memory
- CPU registers
- Non-volatile storage (i.e. hard drive/etc)
- Externally (off on a networked device somewhere)
- Stupid exotic places (IO registers on expansion cards and the like)
As far as pointers go, it’s generally pretty reasonable to forbid using options 3-5 there - whilst there are examples of programs that have done all of those (in some cases even deliberately!), it’s generally not considered a good idea and the vast majority of software doesn’t.
So that leaves:
- Memory
- CPU registers
Which is a pretty short list, although obviously “memory” covers a lot of ground. But in a modern programming environment, memory actually tends to break down into three basic categories:
- Heap memory
- Stack
- Static memory
Let’s consider these in reverse order.
Firstly, static memory is memory that is allocated when the program starts (actually technically it’s generally allocated before the program starts, by the executable loader or similar), and exists for the entire lifespan of the program. It’s not very flexible, but it can be easily accessed from anywhere because it’s always there and the location is known ahead of time.
The stack is dynamically allocated, but it’s generally considered to be a separate entity from the heap (even though in some systems it is actually allocated from the heap) because the program’s access to is usually via specialised instructions that push or pop values to/from it. Most managed environments go a step further than just “usually” and explicitly lock down stack interactions such that the stack can only be manipulated in predefined ways that are predictable and safe.
Heap memory is used for anything dynamically allocated, and the contents can be read and written more-or-less freely. As mentioned above one of our basic premises is that the program is restricted in that it can only access heap memory via pointers given to it by the memory manager that oversees the heap.
Based on this, we can start to see how the application’s graph of pointers works. In order to access a given piece of memory, the program must first start with a pointer stored either in static memory or on the stack. The reason for this is simple - because heap memory can only be accessed if you have a pointer to something in it, the first pointer you retrieve has to be something other than heap memory.
Once you have a pointer, though, you can then follow it and read another pointer (potentially from heap memory this time), walking along the chain of pointers until you reach your destination. If there’s no chain that leads to a particular memory block in the heap, then there’s no way for the program to get there.
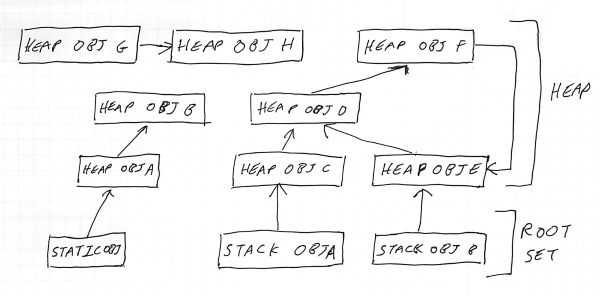
Apologies for the diagrams. Believe it or not, this is what my handwriting looks like when I’m trying.
Since the first pointer in the chain must be in static memory or on the stack, we refer to pointers stored there as the “root set” or “root pointers” - they are the starting points the program uses to find everything else, and since they live in memory that the program can access freely (i.e. without needing to find a pointer elsewhere), the garbage collector needs to assume they are always “live”. These can be seen at the bottom of the diagram (Static obj, Stack obj A and Stack obj B).
As you can see, Heap obj A and Heap obj B are reachable by starting from Static obj, whilst Heap obj C-Heap obj F can be reached from Stack obj A and Stack obj B.
We can say that by definition any heap memory which is accessible to the program must be connected somehow by one of these chains of pointers to a root pointer - in this diagram everything except Heap obj G and Heap obj H are accessible. There is a pointer from Heap obj G to Heap obj H, but it’s irrelevant as there is no way for the program to get a pointer to Heap obj G in order to retrieve it. Thus, they are inaccessible and can be safely removed.
It’s also worth noting here that the object graph can include loops - in the diagram, Heap obj D, Heap obj E and Heap obj F form a loop amongst themselves.
Loops, incidentally, are the reason why naive reference-counting is not a complete solution to the garbage collection problem - in the diagram above
Heap obj DandHeap obj Eeach have two references, but even if the root objectsStack obj AandStack obj Bwere removed, they would only be reduced to a reference count of 1, meaning that theHeap obj D->Heap obj F->Heap obj Eloop would never get removed, even though it is no longer reachable. There are ways to detect this situation, but they tend to end up being special-case versions of the graph walking algorithm we’re describing here.
You may also have noticed at this point that we’ve got slightly ahead of ourselves, and we forgot that in our list of “places the program can store a pointer” there was one other entry - CPU registers. Actually, as it turns out, in a lot of situations you can just ignore CPU registers (kinda), because the easiest solution for a simple garbage collector is simply to ensure that at the point the collection takes place, any pointers to managed objects that may have been in registers have been pushed to the stack (and thus get examined as part of it).
In a single-threaded system, this has a tendency to happen regardless of if you deliberately do it or not (since the act of executing the garbage collector code forces registers to be spilled to the stack), but it’s reasonably straightforward to ensure that happens. In more complex systems (especially multi-threaded ones) this may not be the case, in which case it’s necessary to take a copy of the registers from each thread and store them to check for root pointers.
So having figured out the components that make up the object graph, we’re now at the point where we can actually design a tracing garbage collector. The steps involved are actually very simple:
- Pause the executing program.
- Make sure any pointers in CPU registers are written to the stack.
- Mark every object in the heap as “inaccessible”.
- Walk through the static data areas and the stack and for every heap object pointer we find mark that object as “accessible”.
- Look at each object we just marked as “accessible”, and see if it contains any pointers. If it does, mark the objects they point to as “accessible”.
- Repeat step 4 with each new list of “accessible” objects until there are none left.
- Delete any objects which are still marked as “inaccessible”.
- Resume program execution.
…and you’re done! That’s the basic structure of a “mark/sweep” garbage collector (so called because it first marks objects that are accessible, and then sweeps away those that aren’t). And whilst there are a bunch of small optimisations that can be done to improve the performance (e.g. you can actually resume program execution after step 5, as by that point you know that the objects marked as inaccessible cannot possibly be touched by the program), many real-world garbage collectors follow exactly this pattern.
There is one interesting question this raises, though - how does the collector know where to look for pointers when it’s scanning objects or the stack?
There are a couple of basic solutions to that one - the “precise” one, and the brute-force one. Surprisingly, it turns out that in some ways the brute-force solution is smarter than the precise one!
The precise solution is to use metadata about the program - the layout of structures, primarily - and make a map of where pointers are. From there, we can examine each pointer and see if it falls within the memory range of our heap (remember that whilst the rules said that the program can only access heap memory via pointers it has been given, there’s no rule that says it can’t also have pointers to other memory, such as static data or stack objects). If it does, then it must be a valid pointer (because of the rules), and we can mark the object it points to.
The advantage of this is that (as the name suggests) it’s precise - you only ever mark exactly what you need to - and you can avoid scanning blocks of memory that don’t contain pointers (for example, in C# if someone has declared a 4Mb byte[] to put a texture in, the collector can simply mark the byte array itself as accessible and move on without examining the contents, as it is impossible to cast a byte[] to a pointer).
It is necessary to take a bit of care when examining pointers because the notion of “a pointer to an object” can actually mean one of two things - a direct pointer to the object itself (the obvious case), a pointer to something inside the object (an interior pointer). In the latter case, it’s necessary for the GC to somehow figure out what the base address of the object that contains the pointer is.
The downside is that the metadata can be complex to generate - especially in the case of the stack, where figuring out the precise stack layout at an arbitrary point in executing is quite challenging (although not impossible, especially in C# where stack behaviour is entirely controlled by the runtime environment).
So then we have the brute-force approach. This is simply to scan the entirety of each memory block for anything that looks like a heap pointer. So, for example, we might say that we know any valid heap pointer will fall inside the heap memory area range (for obvious reasons), and also be four-byte-aligned (most languages/runtime enforce some form of minimum alignment). So we look for any number that fits those criteria, and then see if it corresponds to a known heap object.
How to efficiently check if a pointer points to a real heap object is in itself an interesting challenge, but that would be a lengthy diversion for now let’s assume that we do this by looking through a list the memory manager has of allocations.
If the value does match a valid heap object, then we go ahead and assume it is and mark that object as accessible. We don’t spend time worrying if the value we saw was actually part of a texture, or the player’s score, or a random stale pointer that got left behind on the stack - we just assume it must be real and get on with the marking.
The reason this works is because of the goals of automatic memory management we discussed above - we care an awful lot about making sure that we never remove an object that the program is still using, but we don’t actually care as much if we fail to remove one which it isn’t.
It should probably be noted here that this is only true if the garbage collector is purely interested in deleting garbage - more sophisticated collectors may also want to move live objects to reduce heap fragmentation, in which case they need to be able to update pointers to those objects. This in turn means they need to be 100% sure if something is really a pointer or not, because it would be very bad if your garbage collector moved an object and then updated the player’s score to point to the new address!
Thus, this conservative approach is basically a bet that there won’t be too many “random numbers that look like valid heap pointers” lying around. If there are, then the collector will potentially end up marking a load of inaccessible objects as accessible and wasting lots of memory. But if the size of the managed heap is small relative to the overall address space then this risk is reasonably manageable (this is particularly likely to be true in the case where the system is using 64-bit addressing).
There are also some measures runtime environments can take to reduce the changes of getting false-positive heap pointers with a brute-force collector - for example, adding more tight alignment restrictions to pointers, and aggressively clearing unused memory to remove stale pointers or pointer-like-values.
The brute-force approach may sound kinda scary (it certainly scared me when I first encountered it!), but it actually works very well in practice - the Boehm collector used for a long time in Mono and many other projects operates on exactly this basis. Thanks to this, it is able to perform garbage collection on arbitrary C/C++ programs without any additional understanding of the data structures they use, providing that said programs promise not to fold, spindle or mutilate pointers as discussed previously.
In practice, many systems combine the two approaches - for example by using precise scanning on heap objects and static data where the layout is fixed and brute-force for the stack, or separating objects into those which can contain pointers and those which cannot (and thus can be excluded from scanning). The latter is particularly effective in CLR-based languages as CLR rules make it hard to generate structures that contain both large amounts of data and also pointers.
Hopefully that gives you an idea of what the fundamental principles and methodology of a garbage collector are - next up I’d like to take a look at why concurrent garbage collection - where the garbage collector is running at the same time as the program whose garbage is collected - is so much harder to deal with.